开源ETL工具(Kettle) V5.1.0 免费Spoon版
 ACCESS修改密码及压缩工具 1.2
ACCESS修改密码及压缩工具 1.2





 SwsAspWebServer 免费版
SwsAspWebServer 免费版 SQL Server 2014 企业版
SQL Server 2014 企业版 MySQLdb for python 2.7
MySQLdb for python 2.7 mongodb可视化工具(Robomongo) 1.1.1
mongodb可视化工具(Robomongo) 1.1.1 SqliteToAccess(sqlite数据导入access) 2.3
SqliteToAccess(sqlite数据导入access) 2.3 erpcto数据库助手 4.0
erpcto数据库助手 4.0 PDMan(免费数据库建模工具) 2.0.1
PDMan(免费数据库建模工具) 2.0.1 e融合异构数据库同步系统 1.0
e融合异构数据库同步系统 1.0 SSMS Tools Pack(sql智能工具) 4.9.6
SSMS Tools Pack(sql智能工具) 4.9.6- 软件大小:579.00MB (607,125,504 字节)
- 软件类别:编程书集 -> 数据库类
- 软件授权:免费软件 软件语言:多国语言[中文]
- 更新时间:2020/08/07
- 软件厂商:
- 软件官网:
- 应用平台:
Pentaho Data Integration (Kettle)是Pentaho生态系统中默认的ETL工具。Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定(数据迁移工具)。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
通过非常直观的图形化编辑器(Spoon),您可以定义以XML格式储存的流程。在Kettle运行过程中,这些流程会以不同的方法编译。用到的工具包括命令行工具(Pan),小型服务器(Carte),数据库存储库(repository)(Kitchen)或者直接使用IDE(Spoon)。一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定(数据迁移工具)。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
kettle清理数据库连接的方法:
1:清理shared.xml中的不用的数据库连接。(他的保存位置一般在用户主目录下边的.kettle目录中)2:用文本编辑软件打开kjb,ktr文件删除用户到的connection项,保存。
Kettle项目介绍:
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle 将 ELT 流程编译为 XML 格式,学起来十分简单,Pentaho Data Integration (Kettle) 使用 Java (Swing)开发。Kettle 作为编译器对 XML 格式书写的流程进行编译。这些功能和组件比起 Talend 在丰富性方面稍逊一些,但是您建立复杂 ETL 流程需要的一切元素。Kettle 的 JavaScript 引擎(和 Java 引擎)可以深层地控制对数据的处理。 全球数千家机构依赖于Pentaho的,作出更快,更好的业务决策产生积极影响他们的底线。运行 Spoon.bat 开始软件。 需要JRE支持,JRE(Java Runtime Environment) v6.0 Update 26 安装版:http://www.jinshun168.com/soft/22134.html
Kettle使用教程:
Kettle自己有三个主要组件:Spoon,Kitchen,Pan。其中Spoon是一个图形化的界面,用于windows的时候,先设置环境变量:pentaho_java_home,例如:C:\Program Files\Java\jdk1.7.0_25,其实就是你的java安装目录,1.6以上即可。windows下双击Spoon.bat就可以了,界面如下:
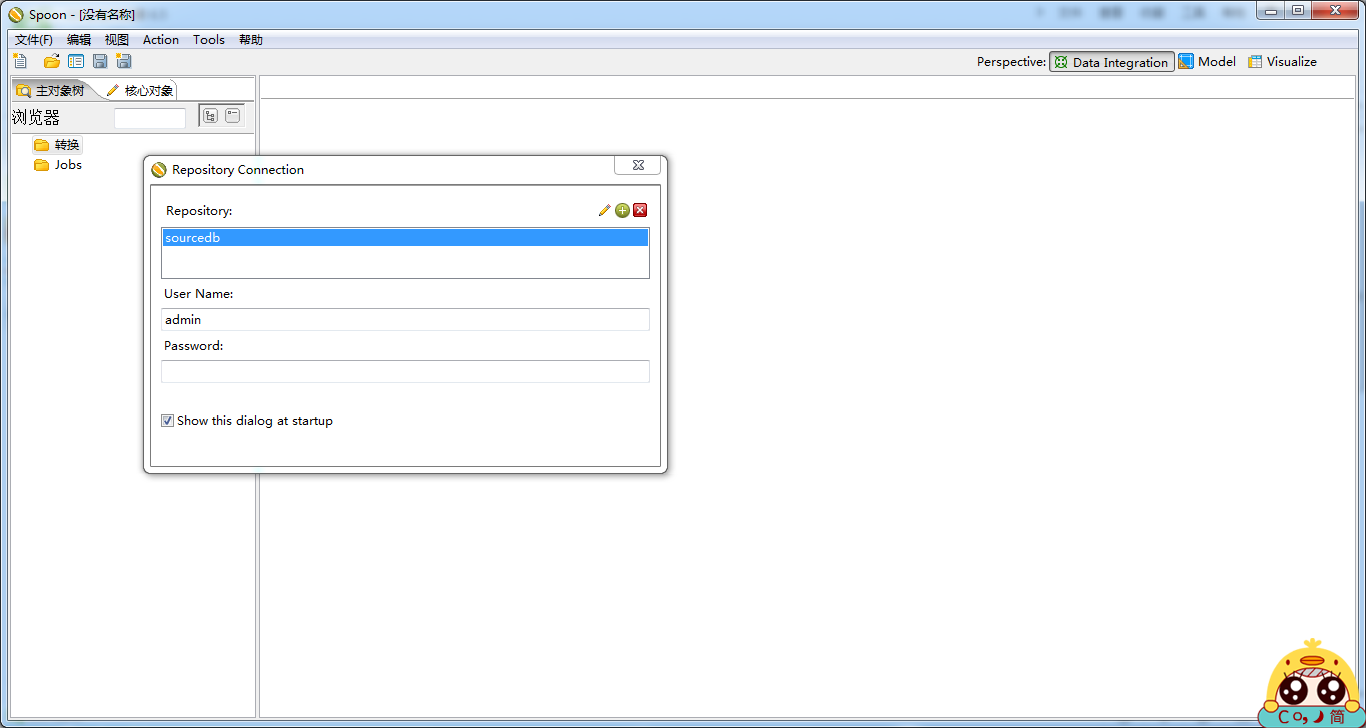
这里我建立了资源库,其实可以用文件形式存储,存储的结构都是xml,但是我还是觉得建立一个资源库比较好,以后看job等情况也比较简单,因为数据表的可读性比xml要好得多。建立资源库和文件资源库只需要把右上角的小加号点一下,就会出现如下如的界面:
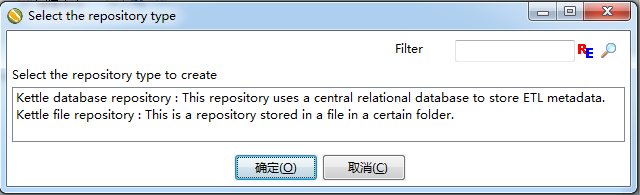
选择第一个就是建立数据库版的资源库,之后:
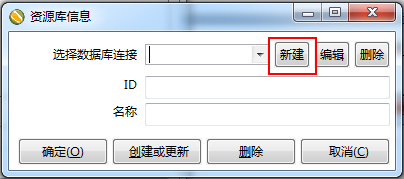
之后:
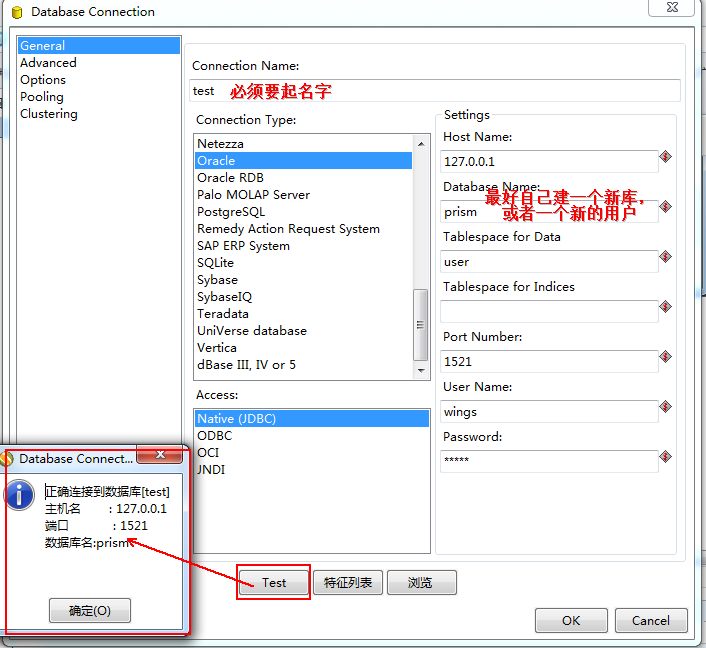
测试通过之后点击OK就回到最开始的界面,这时候选择test数据库连接,然后出入你的工程(我是这么叫的)ID和name,这里要记住,因为以后kitchen调度的时候要输入这个参数。
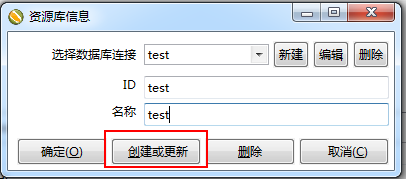
在接下来弹出的框中都点“是”,然后会出现这个界面:
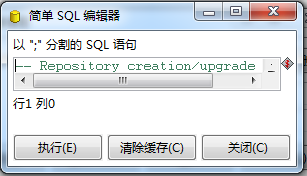
这步会在你的用户下建立很多表,所以最好单独给资源库建立一个用户,当然这是在oracle下,mysql下和DB2下最好也采用同样的方式,把资源库和其他库分开。检查一下:
SQL> conn wings/wings@prism已连接。SQL> select count(1) from r_repository_log;
COUNT(1)----------0
SQL>
表已经建好了。回到最开始的界面,选择test,点击确定,然后就会出现登录对话框,用户密码默认都是admin,以后可以自己改。
接下来就可以开始用这个工具了。
其实对于简单的数据库数据的抽取,基本只需要转换和作业这两种东西。下面就是建立一个转换的步骤:
1 点击文件-->新建-->转换。
2 在左侧的树状列表中选“主对象树”,新建DB连接。步骤和上面建资源库一样。一个目标库一个源库。
3 在核心对象-->输入这个地方拖出一个表输入,在“输出”目录下拖出“表输出”,在“转换”处拖出一个字段选择来,如图:
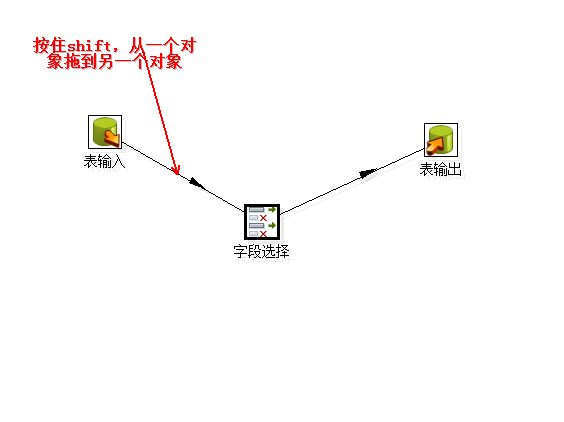
每一个对象都可以双击修改属性,下面以抽取world数据库的city表为例。
双击表输入,选择数据库连接,选择源数据库,然后点击“获取SQL查询语句”,在弹出的对话框里进行选择即可,之后会变成这样:
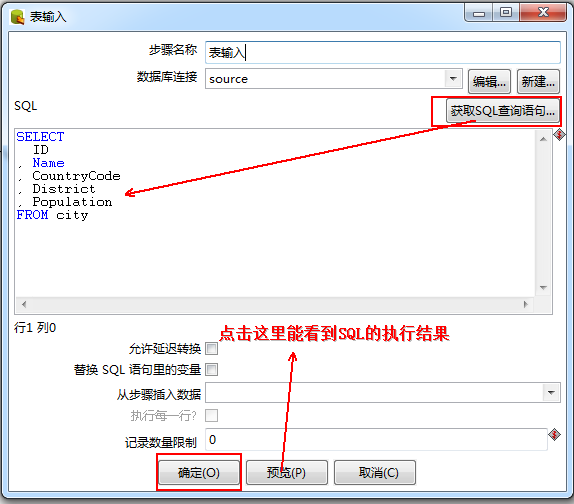
下面点击表输出:
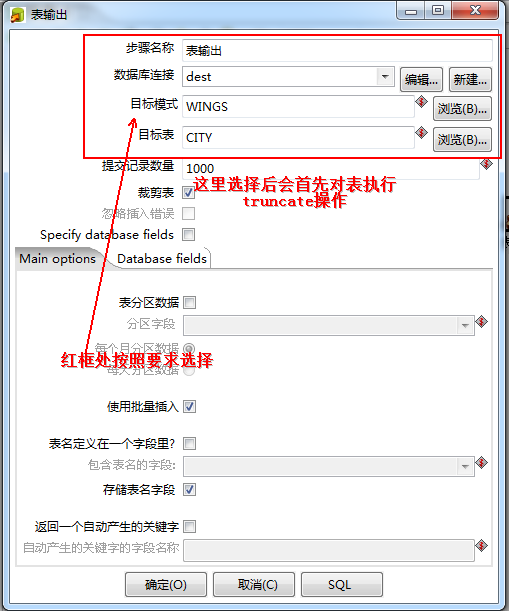
点击字段选择:
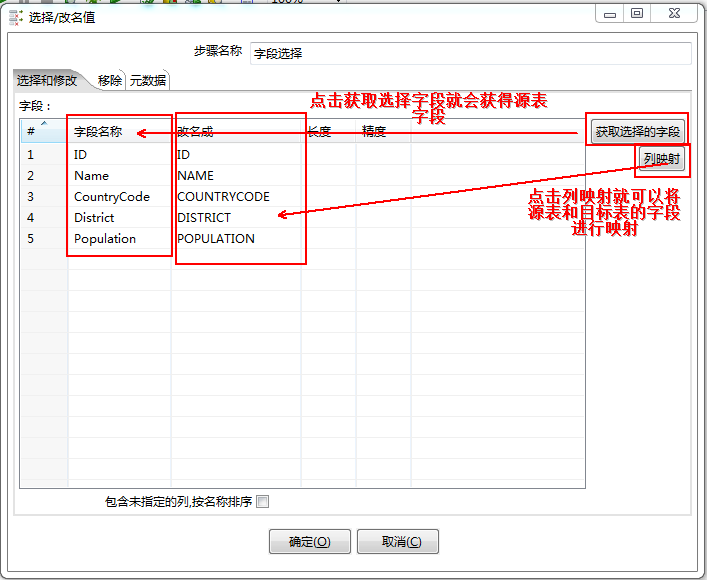
这样,一个简单的抽取数据的转换就完成了。执行之,点击上面的绿色开始按钮。
我也处在学习中,希望可以把我的经验分享给和我一样的入门者。
下面是补充部分:
在一个Job或者一个trans建立好之后,就可以建立定时任务了。如果是DS,那么DS客户端本身就支持schedule,但是Kettle因为没有服务端和客户端的概念,因此只有使用linux的crontab,其实Job本身也支持定时,但是你必须保证图形界面一直开着,这样并不如crontab那么好。在命令行里使用kettle很简单,Job用kitchen调度,trans用pan调度。
下面是一个kitchen的调度命令:
bash /home/kettle/data-integration/kitchen.sh /rep kettle_demo /user username /pass passwd /level Minimal /dir /dirname /job jobname
rep那里写自己的资源库名称。
trans和上面一样,略有不同:
bash /home/kettle/data-integration/pan.sh /rep kettle_demo /user username /pass passwd /level Minimal /dir /dirname /trans transname